
We’re making it clearer how ChatGPT behaves and our goals for enhancing it while also enabling more user customization and soliciting more feedback from the general public.
The Goal of OpenAI is to make sure that all of humanity gains from artificial general intelligence (AGI). As a result, we give a lot of thought to the behaviour of the AI systems we create in the lead-up to AGI, as well as how that behaviour is generated.
Users have shared outputs that they find to be politically biassed, offensive, or otherwise objectionable ever since ChatGPT launched. We believe that many times the concerns voiced have been legitimate and have revealed actual flaws in our systems that we want to fix. A few misunderstandings about how our systems and policies interact to shape the results you receive from ChatGPT have also been observed.
The summary is below.
- What influences ChatGPT’s behaviour;
- How we want to improve ChatGPT’s default behaviour;
- We want to make the system more customizable; and
- our initiatives to increase public participation in our decision-making.
Where we are today
Our models are vast neural networks, which differs from conventional software. Its actions are not explicitly coded; instead, they are learned from a variety of facts. The technique resembles teaching a dog more than regular programming, albeit not being a precise analogy. First, there is a “pre-training” phase when the model learns to anticipate the following word in a sentence using information from exposure to a large amount of Internet material (and to a vast array of perspectives). A second phase follows in which we “fine-tune” our models to focus on certain aspects of system behaviour.
This procedure isn’t perfect yet. Sometimes the process of fine-tuning fails to achieve both our objective, which is to create a safe and usable tool, and the intent of the user (getting a helpful output in response to a given input). Our company’s main aim is to enhance our processes for integrating AI systems with human values, especially as AI systems becoming more powerful.
A two step process: Pre-training and fine-tuning
Building ChatGPT involves the following two primary steps:
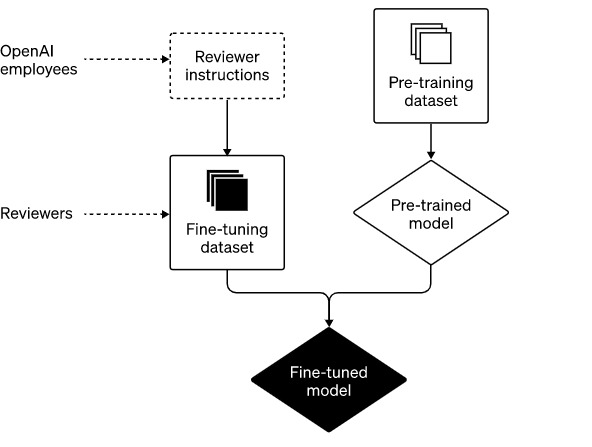
- We “pre-train” models first by asking them to anticipate future events in a sizable dataset that includes portions of the Internet. Kids could be taught to finish the statement “she turned __ instead of turning left.” Our models acquire grammar, a great deal of information about the world, and some level of reasoning by studying billions of texts. They also become aware of some of the prejudices that exist in those countless sentences.
- Then, we carefully create a more limited dataset using human reviewers who adhere to our provided guidelines, and we “fine-tune” these models on it. We do not include specific instructions for each input that ChatGPT will encounter since we cannot foresee all the potential inputs that users may provide in the future. As an alternative, we list a few categories in the standards that our reviewers use to evaluate and score potential model outputs for a variety of example inputs. The models then generalise from this reviewer feedback while they are in use to react to a broad range of specific inputs supplied by a given user.
The role of reviewers and OpenAI’s policies in system development
We may occasionally instruct our reviewers to provide a certain type of output (for instance, “do not complete requests for illegal content”). At times, we provide reviewers with more general advice, such as to “avoid taking a position on difficult topics.” We work closely with reviewers on a continuing basis and benefit greatly from their knowledge. This is important.
Maintaining a strong feedback loop with our reviewers, which means holding weekly meetings to answer any questions they may have or to clarify our guidelines, plays a significant role in the process of fine-tuning. We train the model to become increasingly more accurate over time using this iterative feedback procedure.
Addressing biases
Several people have valid concerns regarding the impact of biases in AI system design and development. We are dedicated to tackling this problem forcefully and being open about both our goals and our development. To that aim, we are disseminating the parts of our rules that deal with politics and hot-button issues. Reviewers are explicitly prohibited from endorsing any political organisation in our standards. The technique outlined above may still result in biases, but these are faults, not features.
Although there will always be differences of opinion, we hope that spreading this blog article and these guidelines will provide more clarity on how we perceive this important part of such a core technology. We think technology corporations should be responsible for creating policies that can withstand examination.
We’re constantly trying to make these rules more understandable, and based on what we’ve learned so far from the ChatGPT launch, we’re planning to give reviewers more guidance on possible problems and difficulties related to prejudice, as well as controversial characters and themes. Also, as this is another possible source of bias in system outputs, we are striving to publish aggregated demographic data on our reviewers in a way that doesn’t go against privacy laws and standards as part of ongoing transparency activities.
Using on external innovations like rule-based rewards and Constitutional AI, we are investigating ways to make the fine-tuning process more intelligible and manageable.
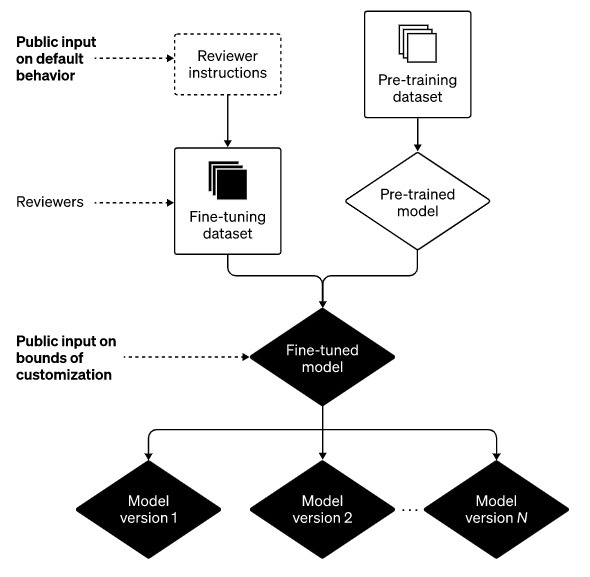
Where we’re going: The building blocks of future systems
We are dedicated to ensuring that everyone has access to, benefits from, and control over AI and AGI in order to fulfil our purpose. In the context of AI system behaviour, we think there are at least three fundamental components that must be present.
1. Improve default behavior. As many people as possible should find our AI systems valuable to them “out of the box” and should believe that our technology respects and is aware of their beliefs.
To that aim, we are making research and technical investments to lessen both obvious and subtle biases in how ChatGPT reacts to various inputs. ChatGPT presently rejects outputs in certain circumstances where it shouldn’t, and in other circumstances where it shouldn’t. We think there is room for development in both areas.
There is also space for improvement in other aspects of system behaviour, such as the system’s tendency to “make things up.” User feedback is crucial for creating these improvements.
2. Define your AI’s values, within broad bounds. We think AI should be a beneficial tool for each individual, adaptable by the user within societally established bounds. As a result, we are creating an update for ChatGPT that will make it simple for users to modify the software’s behaviour.
This will include permitting system outputs that other people—including ourselves—might strongly object to. It will be difficult to strike the correct balance here because going too far with personalization runs the risk of allowing harmful uses of our technology and sycophantic AIs that automatically reinforce people’s preexisting opinions.
As a result, system behaviour will always be constrained in some way. The difficult part is figuring out what those limits are. We will be breaking our promise to “avoid undue concentration of power” in our Charter if we attempt to make all of these decisions on our own or if we attempt to create a single, monolithic AI system.
3. Public input on defaults and hard bounds. Giving those who use or are impacted by systems like ChatGPT the capacity to modify such systems’ regulations is one way to prevent excessive power concentration.
While practical implementation is difficult, we strive to integrate as many perspectives as we can since we feel that many decisions on our defaults and hard bounds should be made jointly. We started by using red teaming to get feedback from outside sources on our technology. We’ve also recently started seeking feedback from the public on AI in education (one particularly important context in which our technology is being deployed).
In order to get feedback from the public on issues like system behaviour, transparency measures (such watermarking), and our deployment policies more generally, we are now piloting these activities. In order to perform independent audits of our safety and policy initiatives, we are also investigating joint ventures with external organisations.
Conclusion
The following depiction of where we’re going can be obtained by adding the three aforementioned building blocks:
We all make mistakes occasionally. When we do, we will build upon what we’ve learned and improve our models and systems.
We value the vigilance of the ChatGPT user community and the general public in holding us accountable, and we’re eager to talk more in the coming months about our work in the three areas mentioned above.
© 2023. All Rights Reserved. Designed by Animesh Mogha

ke
LikeLike
What?
LikeLike